In February of this year Amazon Web Services suffered a pretty bad outage on it’s S3 (Simple Storage Service) platform, which is used by millions of it’s customers, predominantly for hosting websites and the issues caused many of these sites to go dark.
Now, although to some degree one should expect their hosted content to be unavailable at some point, when hosted externally in the public cloud (they don’t offer 100% availability, derr!), it would appear those impacted decided to skimp on resilience.

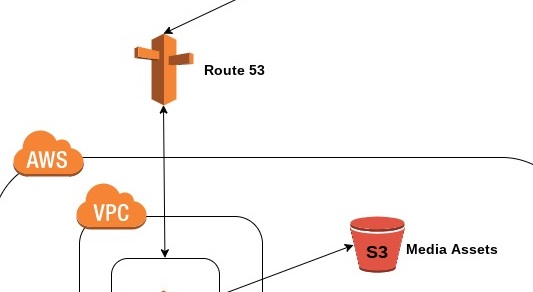
The above diagram illustrates a regular website being hosted on AWS. You type in a domain name, a lookup is performed via AWS’s DNS service – Route 53, you’re forwarded on to a Linux or Windows VM running your web server code and your content is passed to the requester via S3 buckets. If you’re popular enough to have comments/feedback etc then this is stored in a back-end RDS database.
Now let’s take S3 buckets, data is replicated within an Availability Zone (which houses more than two data centres), but not across different AZ’s or geographical regions, you can configure this, but must pay for the benefit.

In this scenario, you mitigate any real possibility of your business critical website going dark, as even if Amazon have S3 issues in an AZ or even a region, the likelihood of two zones going dark would require something pretty spectacular (read: devastating) to occur.
You have DNS resolution occurring using multiple ELBs (Elastic Load Balancers), therefore if one lookup fails you still have a second juicy AZ or region to fall back on and point your requesting users at.
There are a few more bells and whistles to the above diagram, notably a CloudFront distribution to serve cached files to users from geographically closer servers. And also the use of Auto-Scaling groups to automatically scale up and down my web server cluster if demand warrants it.
The recent AWS outage shows us that we all need to think about how important and costly would it be off domain X were to go offline.
I.

Leave a comment